It is very common for applications to contain content and functionality which is not directly linked or reachable from the main visible content. A common example of this is functionality that has been implemented for testing or debugging purposes and has never been removed.
Another example arises where the application presents different functionality to different categories of users (for example, anonymous users, authenticated regular users, and administrators). Users at one privilege level who perform exhaustive spidering of the application may miss functionality that is visible to users at other levels. An attacker who discovers the functionality may be able to exploit it to elevate her privileges within the application. There are countless other cases in which interesting content and functionality may exist that the mapping techniques previously described would not identify, including:
■ Backup copies of live files. In the case of dynamic pages, their file extension may have changed to one that is not mapped as executable, enabling you to review the page source for vulnerabilities that can then be exploited on the main page.
■ Backup archives that contain a full snapshot of files within (or indeed outside) the web root, possibly enabling you to easily identify all content and functionality within the application.
■ New functionality that has been deployed to the server for testing but not yet linked from the main application.
■ Old versions of files that have not been removed from the server. In the case of dynamic pages, these may contain vulnerabilities that have been fixed in the current version but can still be exploited in the old version.
■ Configuration and include files containing sensitive data such as database credentials.
■ Source files out of which the live application’s functionality has been compiled.
■ Log files that may contain sensitive information such as valid usernames, session tokens, URLs visited, actions performed, and so on.
Brute-Force Techniques
In the present context, automation can be used to make huge numbers of requests to the web server, attempting to guess the names or identifiers of hidden functionality.
For example, suppose that your user-directed spidering has identified the following application content:
https://wahh-app.com/login.php
https://wahh-app.com/home/myaccount.php
https://wahh-app.com/home/logout.php
https://wahh-app.com/help/
https://wahh-app.com/register.php
https://wahh-app.com/menu.js
https://wahh-app.com/scripts/validate.js
The first step in an automated effort to identify hidden content might involve the following requests, to locate additional directories:
https://wahh-app.com/access/
https://wahh-app.com/account/
https://wahh-app.com/accounts/
https://wahh-app.com/accounting/
https://wahh-app.com/admin/
https://wahh-app.com/agent/
https://wahh-app.com/agents/
…
Next, the following requests could be made, to locate additional pages:
https://wahh-app.com/access.php
https://wahh-app.com/account.php
https://wahh-app.com/accounts.php
https://wahh-app.com/accounting.php
https://wahh-app.com/admin.php
https://wahh-app.com/agent.php
https://wahh-app.com/agents.php
…
https://wahh-app.com/home/access.php
https://wahh-app.com/home/account.php
https://wahh-app.com/home/accounts.php
https://wahh-app.com/home/accounting.php
https://wahh-app.com/home/admin.php
https://wahh-app.com/home/agent.php
https://wahh-app.com/home/agents.php
…
The various possible responses that may indicate the presence of interesting content mean that is difficult to write a fully automated script to output a listing of valid resources. The best approach is to capture as much information as possible about the application’s responses during the brute-force exercise, and manually review it.
Burp Intruder can be used to iterate through a list of common directory names and capture details of the server’s responses, which can be reviewed to identify valid directories. Figure – 1 shows Burp Intruder being configured to
probe for common directories residing at the web root.
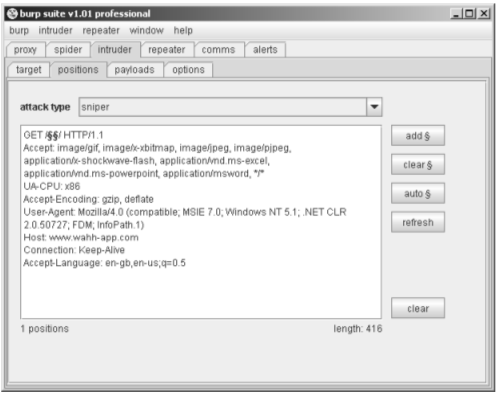
Figure – 1: Burp Intruder being configured to probe for common directories
When the attack has been executed, clicking on column headers such as “status” and “length” will sort the results accordingly, enabling anomalies to be quickly picked out, as shown in Figure – 2.
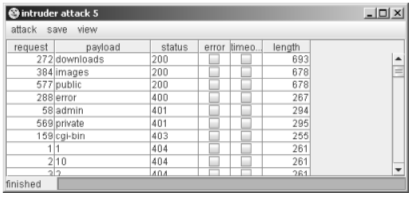
Figure – 2: The results of a test probing for common directories
Inference from Published Content
Most applications employ some kind of naming scheme for their content and functionality. By inferring from the resources already identified within the application, it is possible to fine-tune your automated enumeration exercise to
increase the likelihood of discovering further hidden content.
Use of Public Information
There may be content and functionality within the application that is not presently linked from its main content, but has been linked in the past. In this situation, it is likely that various historical repositories will still contain references to the hidden content. There are two main types of publicly available resources that are useful here:
■Search engines such as Google, Yahoo and MSN. These maintain a fine-grained index of all content which their powerful spiders have discovered, and also cached copies of much of this content, which persists even after the original content has been removed.
■Web archives such as the WayBack Machine located at web.archive.org . These archives maintain a historical record of a very large number of web sites, and in many cases allow users to browse a fully replicated snapshot of a given site as it existed at various dates going back several years.
Leveraging the Web Server
Vulnerabilities may exist at the web server layer that enable you to discover content and functionality that is not linked within the web application itself. For example, there have been numerous bugs within web server software that allow an attacker to list the contents of directories, or obtain the raw source for dynamic server-executable pages. for examples of these vulnerabilities, and ways in which you can identify them. If such a bug exists, you may be able to exploit it to directly obtain a listing of all pages and other resources within the application.
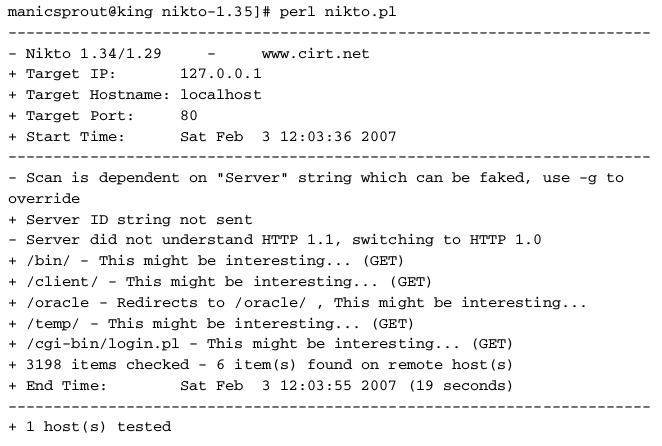
Many web servers ship with default content that may assist you in attacking them — for example, sample and diagnostic scripts that may contain known vulnerabilities, or contain functionality that may be leveraged for some malicious purpose. Further, many web applications incorporate common third-party components that they use for various standard functions — for example, scripts to implement a shopping cart or interface to email servers. Nikto is a handy tool that issues requests for a wide range of default web server content, third-party application components, and common directory names. While Nikto will not rigorously test for any hidden bespoke functionality, it can often be useful in discovering other resources that are not linked within the application and that may be of interest in formulating an attack:
NEXT is..Application Pages vs. Functional Paths…….,