In a typical application, the majority of the content and functionality can be identified via manual browsing. The basic approach is to walk through the application starting from the main initial page, following every link and navigating through all multistage functions (such as user registration or password resetting). If the application contains a “site map,” this can provide a useful starting point for enumerating content.
However, to perform a rigorous inspection of the enumerated content, and to obtain a comprehensive record of everything identified, it is necessary to employ some more advanced techniques than simple browsing.
Web Spidering
Various tools exist which perform automated spidering of web sites. These tools work by requesting a web page, parsing it for links to other content, and then requesting these, continuing recursively until no new content is discovered.
Building on this basic function, web application spiders attempt to achieve a higher level of coverage by also parsing HTML forms and submitting these back to the application using various preset or random values. This can enable them to walk through multistage functionality, and to follow forms-based navigation (e.g., where drop-down lists are used as content menus). Some tools also perform some parsing of client-side JavaScript to extract URLs pointing to further content. The following free tools all do a decent job of enumerating application content and functionality:
■ Paros
■ Burp Spider (part of Burp Suite)
■ WebScarab
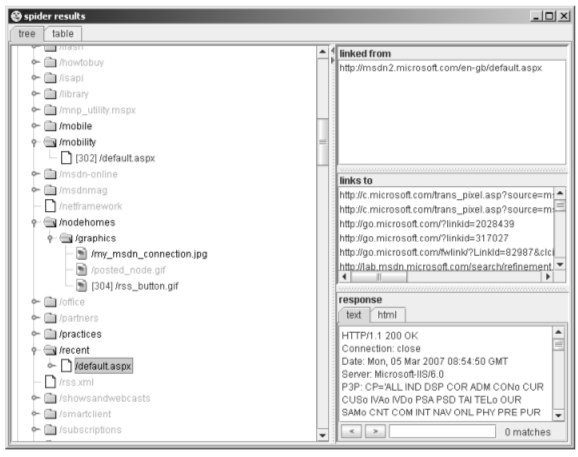
Figure -1: Mapping part of an application using Burp Spider
While it can often be effective, there are some important limitations of this kind of fully automated approach to content enumeration:
■ Unusual navigation mechanisms (such as menus dynamically created and handled using complicated JavaScript code) are often not handled properly by these tools, and so they may miss whole areas of an application.
■ Multistage functionality often implements fine-grained input validation checks, which do not accept the values that may be submitted by an automated tool. For example, a user registration form may contain fields for name, email address, telephone number, and ZIP code. An automated application spider will typically submit a single test string in each editable form field, and the application will return an error message saying that one or more of the items submitted were invalid. Because the spider is not intelligent enough to understand and act upon this message, it will not proceed past the registration form and so will not discover any further content or functions accessible beyond it.
■ Automated spiders typically use URLs as identifiers of unique content. To avoid continuing spidering indefinitely, they recognize when linked content has already been requested and do not request it again. However, many applications use forms-based navigation in which the same URL may return very different content and functions. For example, a banking application may implement every user action via a POST request to /account.jsp , and use parameters to communicate the action being performed. If a spider refuses to make multiple requests to this URL, it will miss most of the application’s content. Some application spiders attempt to handle this situation (for example, Burp Spider can be configured to individuate form submissions based on parameter names and values); however, there may still be situations where a fully automated approach is not completely effective.
■ Conversely to the previous point, some applications place volatile data within URLs that is not actually used to identify resources or functions (for example, parameters containing timers or random number seeds). Each page of the application may contain what appears to be a new set of URLs that the spider must request, causing it to continue running indefinitely.
■ Where an application uses authentication, an effective application spider must be able to handle this in order to access the functionality that it protects. The spiders mentioned previously can achieve this, by manually configuring them either with a token for an authenticated session or with credentials to submit to the login function. However, even when this is done, it is common to find that the operation of the spider reaks the authenticated session for various reasons:
■ By following all URLs, the spider will at some point request the logout function, causing its session to break.
■ If the spider submits invalid input to a sensitive function, the application may defensively terminate the session.
■ If the application uses per-page tokens, the spider will almost certainly fail to handle these properly by requesting pages out of their expected sequence, probably causing the entire session to be terminated.
NEXT is..User-Directed Spidering………,