The enumeration techniques described so far have been implicitly driven by one particular picture of how web application content may be conceptualized and catalogued. This picture is inherited from the pre application days of the World Wide Web, in which web servers functioned as repositories of static information, retrieved using URLs that were effectively filenames. To publish some web content, an author simply generated a bunch of HTML files and
copied these into the relevant directory on a web server. When users followed hyperlinks, they navigated around the set of files created by the author, requesting each file via its name within the directory tree residing on the server.
Although the evolution of web applications has fundamentally changed the experience of interacting with the Web, the picture just described is still applicable to the majority of web application content and functionality. Individual functions are typically accessed via a unique URL, which is usually the name of the server-side script that implements the function. The parameters to the request (residing in either the URL query string or the body of a POST request) do not tell the application what function to perform — they tell it what information to use when performing it. In this context, the methodology of constructing a URL-based map can be effective in cataloging the functionality of the application.
In some applications, however, the picture based on application “pages” is inappropriate. While it may be logically possible to shoehorn any application’s structure into this form of representation, there are many cases in which a different picture, based on functional paths, is far more useful for cataloging its content and functionality. Consider an application that is accessed using only requests of the following form:
POST /bank.jsp HTTP/1.1
Host: wahh-bank.com
Content-Length: 106
servlet=TransferFunds&method=confirmTransfer&fromAccount=10372918&toAcco
unt=3910852&amount=291.23&Submit=Ok
Here, every request is made to a single URL. The parameters to the request are used to tell the application what function to perform, by naming the Java servlet and method to invoke. Further parameters provide the information to use in performing the function. In the picture based on application pages, the application will appear to have only a single function, and a URL-based map will not elucidate its functionality. However, if we map the application in terms of functional paths, we can obtain a much more informative and useful catalogue of its functionality. Figure 1 is a partial map of the functional paths that exist within the application.
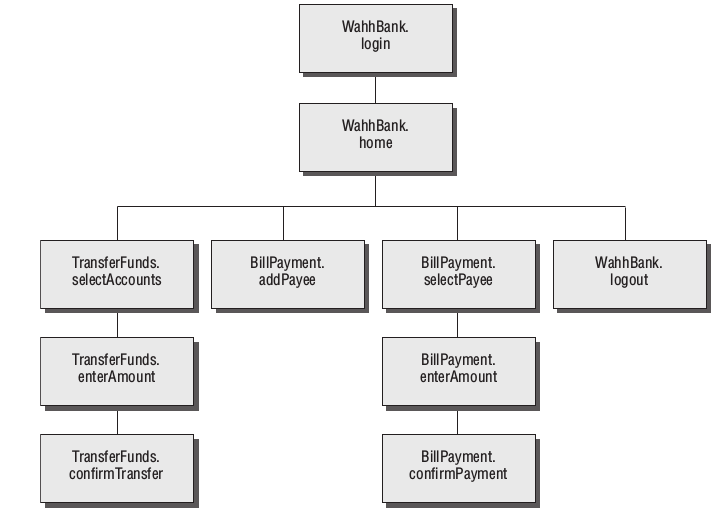
Figure -1: A mapping of the functional paths within a web application
Representing an application’s functionality in this way is often more useful even in cases where the usual picture based on application pages can be applied without any problems. The logical relationships and dependencies between different functions may not correspond to the directory structure used within URLs. It is these logical relationships that are of most interest to you, both in understanding the core functionality of the application, and in formulating possible attacks against it. By identifying these, you can better understand the expectations and assumptions of the application’s developers when implementing the functions, and attempt to find ways of violating these assumptions, causing unexpected behavior within the application.
In applications where functions are identified using a request parameter, rather than the URL, this has implications for the enumeration of application content. In the previous example, the content discovery exercises described so far are unlikely to uncover any hidden content. Those techniques need to be adapted to the mechanisms actually used by the application for accessing functionality.
Discovering Hidden Parameters
A variation on the situation where an application uses request parameters to specify which function should be performed arises where other parameters are used to control the application’s logic in significant ways. For example, an application may behave differently if the parameter debug=true is added to the query string of any URL — it might turn off certain input validation checks, allow the user to bypass certain access controls, or display verbose debug information in its response. In many cases, the fact that the application handles this parameter cannot be directly inferred from any of its content (for example, it does not include debug=false in the URLs that it publishes as
hyperlinks). The effect of the parameter can only be detected by guessing a range of values until the correct one is submitted.
NEXT is..Analyzing the Application…..,