The hypertext transfer protocol (HTTP) is the core communications protocol used to access the World Wide Web and is used by all of today’s web applications. It is a simple protocol that was originally developed for retrieving static text-based resources, and has since been extended and leveraged in various ways to enable it to support the complex distributed applications that are now commonplace.
HTTP uses a message-based model in which a client sends a request message, and the server returns a response message. The protocol is essentially connectionless: although HTTP uses the stateful TCP protocol as its transport mechanism, each exchange of request and response is an autonomous transaction, and may use a different TCP connection.
HTTP Requests
All HTTP messages (requests and responses) consist of one or more headers, each on a separate line, followed by a mandatory blank line, followed by an optional message body. A typical HTTP request is as follows:
GET /books/search.asp?q=wahh HTTP/1.1
Accept: image/gif, image/xxbitmap, image/jpeg, image/pjpeg,
application/xshockwaveflash, application/vnd.msexcel,
application/vnd.mspowerpoint, application/msword, */*
Referer: http://wahh-app.com/books/default.asp
Accept-Language: en-gb,en-us;q=0.5
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)
Host: wahh-app.com
Cookie: lang=en; JSESSIONID=0000tI8rk7joMx44S2Uu85nSWc_:vsnlc502
The first line of every HTTP request consists of three items, separated by spaces:
■ A verb indicating the HTTP method. The most commonly used method is GET , whose function is to retrieve a resource from the web server. GET requests do not have a message body, so there is no further data following the blank line after the message headers.
■ The requested URL. The URL functions as a name for the resource being requested, together with an optional query string containing parameters that the client is passing to that resource. The query string is indicated by the ? character in the URL, and in the example there is a single parameter with the name q and the value wahh .
■ The HTTP version being used. The only HTTP versions in common use on the Internet are 1.0 and 1.1, and most browsers use version 1.1 by default. There are a few differences between the specifications of these two versions; however, the only difference you are likely to encounter when attacking web applications is that in version 1.1 the Host request header is mandatory.
Some other points of interest in the example request are:
■ The Referer header is used to indicate the URL from which the request originated (for example, because the user clicked a link on that page). Note that this header was misspelled in the original HTTP specification, and the misspelled version has been retained ever since.
■ The User-Agent header is used to provide information about the browser or other client software that generated the request. Note that the Mozilla prefix is included by most browsers for historical reasons — this was the User-Agent string used by the originally dominant Net – scape browser, and other browsers wished to assert to web sites that they were compatible with this standard. As with many quirks from computing history, it has become so established that it is still retained, even on the current version of Internet Explorer, which made the request shown in the example.
■ The Host header is used to specify the hostname that appeared in the full URL being accessed. This is necessary when multiple web sites are hosted on the same server, because the URL sent in the first line of the request does not normally contain a hostname. (See Chapter 16 for more information about virtually hosted web sites.)
■ The Cookie header is used to submit additional parameters that the server has issued to the client.
HTTP Responses
A typical HTTP response is as follows:
HTTP/1.1 200 OK
Date: Sat, 19 May 2007 13:49:37 GMT
Server: IBM_HTTP_SERVER/1.3.26.2 Apache/1.3.26 (Unix)
Set-Cookie: tracking=tI8rk7joMx44S2Uu85nSWc
Pragma: no-cache
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Language: en-US
Content-Length: 24246
<!DOCTYPE html PUBLIC “-//W3C//DTD HTML 4.01 Transitional//EN”>
<html lang=”en”>
<head>
<meta http-equiv=”Content-Type” content=”text/html;
charset=iso-8859-1”>
…
The first line of every HTTP response consists of three items, separated by spaces:
■ The HTTP version being used.
■ A numeric status code indicating the result of the request. 200 is the most common status code; it means that the request was successful and the requested resource is being returned.
■ A textual “reason phrase” further describing the status of the response. This can have any value and is not used for any purpose by current browsers.
Some other points of interest in the previous response are:
■ The Server header contains a banner indicating the web server software being used, and sometimes other details such as installed modules and the server operating system. The information contained may or may not be accurate.
■ The Set-Cookie header is issuing the browser a further cookie; this will be submitted back in the Cookie header of subsequent requests to this server.
■ The Pragma header is instructing the browser not to store the response in its cache, and the Expires header also indicates that the response content expired in the past and so should not be cached. These instructions are frequently issued when dynamic content is being returned, to ensure that browsers obtain a fresh version of this content on subsequent occasions.
■ Almost all HTTP responses contain a message body following the blank line after the headers, and the Content-Type header indicates that the body of this message contains an HTML document.
■ The Content-Length header indicates the length of the message body in bytes.
HTTP Methods
When you are attacking web applications, you will be dealing almost exclusively with the most commonly used methods: GET and POST . There are some important differences between these methods which you need to be aware of, and which can affect an application’s security if overlooked.
The GET method is designed for retrieval of resources. It can be used to send parameters to the requested resource in the URL query string. This enables users to bookmark a URL for a dynamic resource that can be reused by themselves or other users to retrieve the equivalent resource on a subsequent occasion (as in a bookmarked search query). URLs are displayed on-screen, and are logged in various places, such as the browser history and the web server’s access logs. They are also transmitted in the Referer header to other sites when external links are followed. For these reasons, the query string should not be used to transmit any sensitive information.
The POST method is designed for performing actions. With this method, request parameters can be sent both in the URL query string and in the body of the message. Although the URL can still be bookmarked, any parameters sent in the message body will be excluded from the bookmark. These parameters will also be excluded from the various locations in which logs of URLs are maintained and from the Referer header. Because the POST method is designed for performing actions, if a user clicks the Back button of the browser to return to a page that was accessed using this method, the browser will not automatically reissue the request but will warn the user of what it is about to do, as shown in Figure -1. This prevents users from unwittingly performing an action more than once. For this reason, POST requests should always be used when an action is being performed.
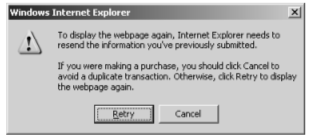
Figure -1: Browsers do not automatically reissue POST requests made by users,
because these might result in an action being performed more than once
In addition to the GET and POST methods, the HTTP protocol supports numerous other methods that have been created for specific purposes. The other methods you are most likely to require knowledge of are:
■ HEAD — This functions in the same way as a GET request except that the server should not return a message body in its response. The server should return the same headers that it would have returned to the cor- responding GET request. Hence, this method can be used for checking whether a resource is present before making a GET request for it.
■ TRACE — This method is designed for diagnostic purposes. The server should return in the response body the exact contents of the request message that it received. This can be used to detect the effect of any proxy servers between the client and server that may manipulate the request. It can also sometimes be used as part of an attack against other application users.
■ OPTIONS — This method asks the server to report the HTTP methods that are available for a particular resource. The server will typically return a response containing an Allow header that lists the available methods.
■ PUT — This method attempts to upload the specified resource to the server, using the content contained in the body of the request. If this method is enabled, then you may be able to leverage it to attack the application; for example, by uploading an arbitrary script and executing this on the server.
Many other HTTP methods exist that are not directly relevant to attacking web applications. However, a web server may expose itself to attack if certain dangerous methods are available.
URLs
A uniform resource locator (URL) is a unique identifier for a web resource, via which that resource can be retrieved. The format of most URLs is as follows:
protocol://hostname[:port]/[path/]file[?param=value]
Several components in this scheme are optional, and the port number is nor- mally only included if it diverges from the default used by the relevant protocol. The URL used to generate the HTTP request shown earlier is:
http://wahh-app.comm/books/search.asp?q=wahh
In addition to this absolute form, URLs may be specified relative to a particular host, or relative to a particular path on that host, for example:
/books/search.asp?q=wahh
search.asp?q=wahh
These relative forms are often used in web pages to describe navigation within the web site or application itself.
NEXT is..HTTP Headers…..,