Path traversal vulnerabilities are often subtle and hard to detect, and it may be necessary to prioritize your efforts on locations within the application that are most likely to manifest the vulnerability.
Locating Targets for Attack
During your initial mapping of the application, you should already have identified any obvious areas of attack surface in relation to path traversal vulnerabilities. Any functionality whose explicit purpose is uploading or downloading files should be thoroughly tested. This functionality is often found in workflow applications where users can share documents, in blogging and auction applications where users can upload images, and in informational applications where users can retrieve documents such as ebooks, technical manuals, and company reports.
In addition to obvious target functionality of this kind, there are various other types of behavior that may suggest relevant interaction with the file system.
Detecting Path Traversal Vulnerabilities
Having identified the various potential targets for path traversal testing, you need to test every instance individually to determine whether user-controllable data is being passed to relevant file system operations in an unsafe manner.
For each user-supplied parameter being tested, determine whether traversal sequences are being blocked by the application or whether they work as expected. An initial test that is usually reliable is to submit traversal sequences in a way that does not involve stepping back above the starting directory.
If you find any instances where submitting traversal sequences without stepping above the starting directory does not affect the application’s behavior, the next test is to attempt to traverse out of the starting directory and access files from elsewhere on the server file system.
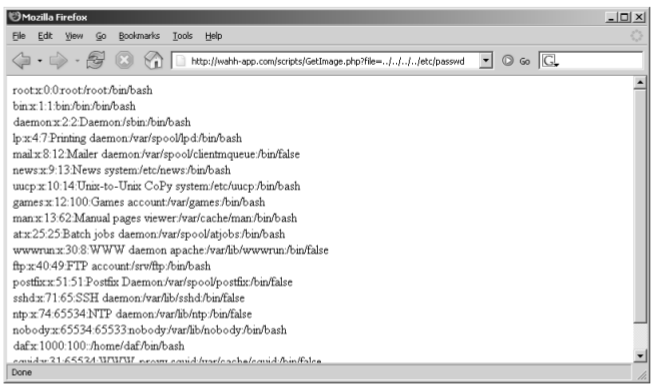
Figure -1: A successful path traversal attack
Circumventing Obstacles to Traversal Attacks
If your initial attempts to perform a traversal attack, as described previously, are unsuccessful, this does not mean that the application is not vulnerable. Many application developers are aware of path traversal vulnerabilities and implement various kinds of input validation checks in an attempt to prevent them. However, those defenses are often flawed and can be bypassed by a skilled attacker.
The first type of input filter commonly encountered involves checking whether the filename parameter contains any path traversal sequences, and if so, either rejects the request or attempts to sanitize the input to remove the sequences. This type of filter is often vulnerable to various attacks that use alternative encodings and other tricks to defeat the filter. These attacks all exploit the type of canonicalization problems faced by input validation mechanisms.
Coping with Custom Encoding
Probably the craziest path traversal bug that the authors have encountered involved a custom encoding scheme for filenames that were ultimately handled in an unsafe way, and demonstrated how obfuscation provides no substitute for security.
The application contained some workflow functionality that enabled users to upload and download files. The request performing the upload supplied a filename parameter that was vulnerable to a path traversal attack when writing the file. When a file had been successfully uploaded, the application provided users with a URL to download it again. There were two important caveats:
■ The application verified whether the file to be written already existed, and if so, refused to overwrite it.
■ The URLs generated for downloading users’ files were represented using a bespoke obfuscation scheme — this appeared to be a customized form of Base64-encoding, in which a different character set was employed at each position of the encoded filename.
Taken together, these caveats presented a barrier to straightforward exploitation of the vulnerability. First, although it was possible to write arbitrary files to the server file system, it was not possible to overwrite any existing file, and the low privileges of the web server process meant that it was not possible to create a new file in any interesting locations. Second, it was not possible to request an arbitrary existing file (such as /etc/passwd ) without reverse engineering the custom encoding, which presented a lengthy and unappealing challenge.
A little experimentation revealed that the obfuscated URLs contained the original filename string supplied by the user. For example:
■ test.txt became zM1YTU4NTY2Y .
■ foo/../test.txt became E1NzUyMzE0ZjQ0NjMzND .
The difference in length of the encoded URLs indicated that no path canonicalization had been performed before applying the encoding. This behavior gave us enough of a toe-hold to exploit the vulnerability. The first step was to submit a file with the following name:
../../../../../.././etc/passwd/../../tmp/foo
which in its canonical form is equivalent to
/tmp/foo
and so could be written by the web server. Uploading this file produced a download URL containing the following obfuscated filename:
FhwUk1rNXFUVEJOZW1kNlRsUk5NazE2V1RKTmFrMHdUbXBWZWs1NldYaE5lb
To modify this value to return the file /etc/passwd , we simply needed to truncate it at the right point, which is
FhwUk1rNXFUVEJOZW1kNlRsUk5NazE2V1RKTmFrM
Attempting to download a file using this value returned the server’s passwd file as expected. The server had given us sufficient resources to be able to encode arbitrary file paths using its scheme, without even deciphering the obfuscation algorithm being used!
Exploiting Traversal Vulnerabilities
Having identified a path traversal vulnerability that provides read or write access to arbitrary files on the server’s file system, what kind of attacks can you carry out by exploiting these? In most cases, you will find that you have the same level of read/write access to the file system as the web server process does.
NEXT is..Preventing Path Traversal Vulnerabilities………………………….,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,