In a Unix system, several concurrent processes attend to different tasks. Each process asks for system resources, be it computing power, memory, network connectivity, or some other resource. The kernel is the big chunk of executable code in charge of handling all such requests. Though the distinction between the different kernel tasks isn’t always clearly marked, the kernel’s role can be split, as shown in Figure 1, into the following parts:
Process management
The kernel is in charge of creating and destroying processes and handling their connection to the outside world (input and output). Communication among different processes (through signals, pipes, or interprocess communication primitives) is basic to the overall system functionality and is also handled by the kernel. In addition, the scheduler, which controls how processes share the CPU, is part of process management. More generally, the kernel’s process management activity implements the abstraction of several processes on top of a single CPU or a few of them.
Memory management
The computer’s memory is a major resource, and the policy used to deal with it is a critical one for system performance. The kernel builds up a virtual addressing space for any and all processes on top of the limited available resources. The different parts of the kernel interact with the memory management subsystem through a set of function calls, ranging from the simple malloc/free pair to much more exotic functionalities.
File systems
Unix is heavily based on the file system concept; almost everything in Unix can be treated as a file. The kernel builds a structured file system on top of unstructured hardware, and the resulting file abstraction is heavily used
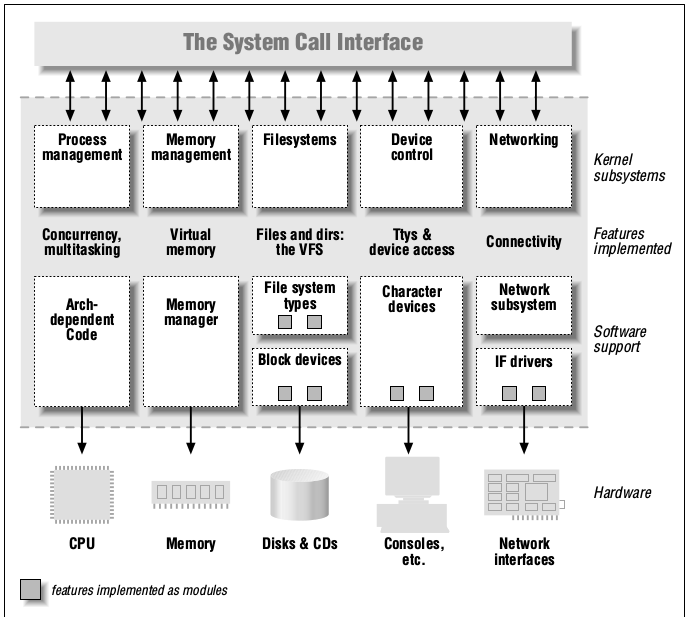
Figure 1. A split view of the kernel
throughout the whole system. In addition, Linux supports multiple file system types, that is, different ways of organizing data on the physical medium. For example, diskettes may be formatted with either the Linux-standard ext2 file system or with the commonly used FAT file system.
Device control
Almost every system operation eventually maps to a physical device. With the exception of the processor, memory, and a very few other entities, any and all device control operations are per formed by code that is specific to the device being addressed. That code is called a device driver. The kernel must have embedded in it a device driver for every peripheral present on a system, from the hard drive to the keyboard and the tape streamer. This aspect of the kernel’s functions is our primary interest.
Networking
Networking must be managed by the operating system because most network operations are not specific to a process: incoming packets are asynchronous events. The packets must be collected, identified, and dispatched before a process takes care of them. The system is in charge of delivering data packets across program and network interfaces, and it must control the execution of programs according to their network activity. Additionally, all the routing and address resolution issues are implemented within the kernel.
One of the good features of Linux is the ability to extend at runtime the set of featur es of fered by the kernel. This means that you can add functionality to the kernel while the system is up and running.
Each piece of code that can be added to the kernel at runtime is called a module. The Linux kernel offers support for quite a few different types (or classes) of modules, including, but not limited to, device drivers. Each module is made up of object code (not linked into a complete executable) that can be dynamically linked to the running kernel by the insmod program and can be unlinked by the rmmod program.
Figure 1 identifies different classes of modules in charge of specific tasks—a module is said to belong to a specific class according to the functionality it offers. The placement of modules in Figure 1 covers the most important classes, but is far from complete because more and more functionality in Linux is being modularized.