Clustering
The word “clustering” can mean different things to different people. Some people would say clustering is simply having a replicated system on standby available to be turned on when the primary system fails. To others, clustering is having several systems working
in concert with one another, with replicated data, fully redundant, and infinitely expandable. For most people, it’s probably somewhere between those two extremes.
In this topic, we’re going to explore the possibilities for clustering that exist with Asterisk at a high level, giving you the knowledge and direction to start planning your system into the future. As examples, we’ll discuss some of the tools that we’ve used in our own large deployments. While there is no single way to go about building an Asterisk cluster, the topologies we’ll cover have proven reliable and popular over time.
Our examples will delve into building a distributed call center, one of the more popular reasons for building a distributed system. In some cases this is necessary simply because a company has satellite offices it wants to tie into the primary system. For others, the goal is to integrate remote employees, or to be able to handle a large number of seats. We’ll start by looking at a simple, traditional PBX system, and see how that system can eventually grow into something much larger.
Traditional PBXs
Most PBX systems deployed before the year 2000 look quite similar. They typically involve a group of telephone circuits delivered either via PRI or through an array of analog lines, connecting the outside world through the PBX, to a group of proprietary handsets and peripheral applications. These systems provide a common set of PBX functions, with extra capabilities such as voicemail and conferencing provided through external hardware modules (typically adding thousands of dollars of cost to the system).
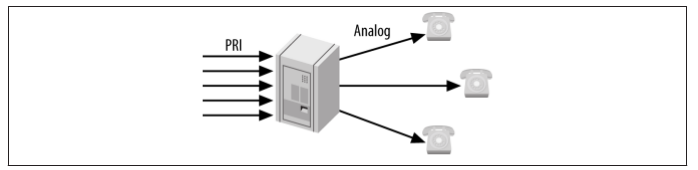
Figure -1. Traditional call center
Such systems utilize a set of rules for delivering calls to agents through the standard automatic call distribution (ACD) rules, and have little flexibility. It is likely either impossible or expensive to add remote agents, as calls need to be delivered over the PSTN, which utilizes two phone lines: one for the incoming caller to the queue, and another to be delivered to the remote agent (in most cases, the agents just need to reside at the same physical location as the PBX itself).
These traditional phone systems are slowly being phased out, though, as more people start clamoring for the features VoIP brings to the table. And even for systems that won’t be using VoIP, solutions like Asterisk bring to the table features that once cost thousands of dollars as an included part of the software.
Of course, with the money invested in expensive hardware in traditional systems, it is natural that organizations with these systems will want to get as much use from them as possible. Plus, simply swapping out an existing system is not only expensive (wiring costs for SIP phones, replacement costs for proprietary handsets, etc.), but may be disruptive to the call center, especially if it operates continuously.
Perhaps, though, the time to expand has come, and the existing system is no longer able to keep up with the number of lines required and the number of seats necessary to keep up with demand. In this case, it may be advantageous to look toward a hybrid system, where the existing hardware continues to be used, but new seats and features are added to the system using Asterisk.
Hybrid Systems
A hybrid phone system (Figure -2) contains the same functionality and hardware as a traditional phone system, but it has another system such as Asterisk attached to it, providing additional capacity and functionality. Adding Asterisk to a traditional system is typically done via a PRI connection. From the viewpoint of the traditional system, Asterisk will look like another phone company (central office, or CO). Depending on the way the traditional system operates and the services available to or from the CO, either Asterisk will deliver calls from the PRI through itself and to the existing PBX, or the existing PBX will send calls over the PRI connection to Asterisk, which will then direct the calls to the new endpoints (phones).
Figure -2. Remote hybrid system
With Asterisk in the picture, functionality can be moved piecemeal from the existing PBX system over to Asterisk, which can take on a greater role and command more of the system over time. Eventually, the existing PBX system may simply be used as a method for sending calls to the existing handsets on the agents’ desks, with those being phased out over time and replaced with SIP-based phones, as the wiring is installed and phones are purchased.
By adding Asterisk to the existing system, we gain a new set of functionality and advantages, such as:
• Support for remote employees, with calls delivered over the existing Internet connection
• Features such as conferencing and voicemail (with the possibility of users being notified via email of new messages)
• Expanded phone lines using VoIP, and a reduction in long-distance costs
Such a system still suffers from a few disadvantages, as all the hardware needs to reside at the call center facility, and we’re still restricted to using (relatively) expensive hardware in the Asterisk system for connecting to the traditional PBX. We’re moving in the right direction, though, and with the Asterisk system in place we can start the migration over time, limiting interruptions to the business and taking a more gradual approach to training users.
Pure Asterisk, Nondistributed
The next step in our journey is the pure Asterisk system. In this system we’ve successfully migrated away from the existing PBX system and are now handling all functionality through Asterisk. Our existing PRI has been attached to Asterisk, and we’ve expanded our capacity by integrating an Internet telephony service provider (ITSP) into our system. All agents are now using SIP phones, and we’ve even added several remote employees.
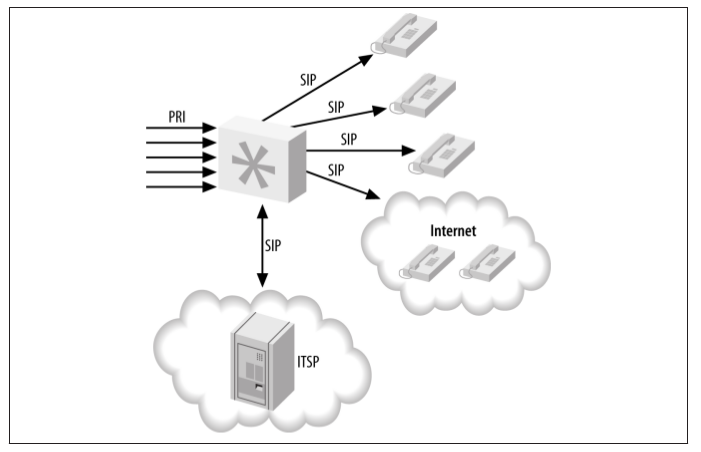
Figure -3. Nondistributed Asterisk
Remote employees can be a great advantage for a company. Not only can letting your employees work from remote locations increase morale by alleviating the burden of a potentially long commute, but it allows people to work in an environment they are comfortable in, which can make them more productive. Furthermore, the call center manager does not have any less control over employee statistics: remote workers’ calls can still be monitored for training purposes, and the statistical data gathered look no different to the manager than for employees working onsite.
A measurable advantage for the company is the reduction in the amount of hardware needed for each employee. If agents can utilize their existing computer systems, electrical grids, and Internet connections, the company can save a significant amount of money by supporting remote employees. Additionally, those employees can be located across the globe to expand the number of hours your agents are available, thereby allowing you to serve more time zones.
Asterisk and Database Integration
Integrating Asterisk with a database can add a great deal of functionality to your system. Additionally, it provides a way to build web-based configuration utilities to make the maintenance of an Asterisk system easier. What’s more, it allows instant access to information from the dialplan and other parts of the Asterisk system.
Single Database
Adding database integration to Asterisk is a powerful way of gaining access to information that can be manipulated by other means. For example, we can read information about the extensions and devices in the system from a database using the Asterisk Realtime Architecture, and we can modify the information stored in the database via an external system, such as a web page.
Integration with a database adds a layer between Asterisk and a web interface that the web designer is familiar with, and allows the manipulation of data in a way that doesn’t require new skill sets. Knowledge of Asterisk itself is left to the Asterisk administrator, and the web developer can happily work with tools she is familiar with.
Of course, this makes the Asterisk system slightly more complex to build, but integration with a database via ODBC adds all sorts of possibilities. func_odbc is a powerful tool for the Asterisk administrator, providing the ability to build a static dialplan using data that is dynamic in nature.
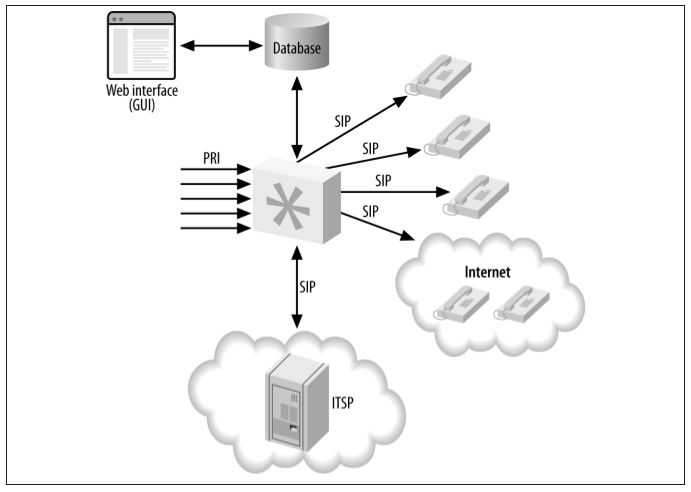
Figure-4. Asterisk database integration, single server
With the data abstracted from Asterisk directly, we will now have an easier time moving toward a system that is getting ready to be clustered. We can use something like Linux-HA to provide automatic failover between systems. While in the event of a failure the calls on the system that failed will be lost, the failover will take only moments (less than a second) to be detected, and the system will appear to its users to be immediately available again. In this configuration, since our data is abstracted outside of Asterisk, we can use applications such as unison or rsync to keep the configuration files synchronized between the primary and the backup system. We could also use subversion or git to track changes to the configuration files, making it easy to roll back changes that don’t
work out.
Of course, if our database goes away due to a failure of the hardware or the software, our system will be unavailable unless it is programmed so as to be able to work without the database connection. This could be accomplished either by using a local database that simply updates itself periodically from the primary database, or through information programmed directly into the dialplan. In most cases the functionality of the system in this mode will be simpler than when the database was available, but at least the system will not be entirely unusable.
A better solution would be to use a replicated database, which allows data written to one database server to be written to another server at the same time. Asterisk can then fail over to the other database automatically if the primary server becomes unavailable.
Replicated Databases
Using a replicated database provides some redundancy in the backend to help limit the amount of downtime callers and agents experience if a database failure occurs. A master- master database configuration is required so that data can be written to either database and automatically replicated to the other system, ensuring that we have an exact copy of the data on two physical machines. Another advantage to this approach is that a single system no longer needs to handle all the transactions to the database; the load can be divided among the servers.
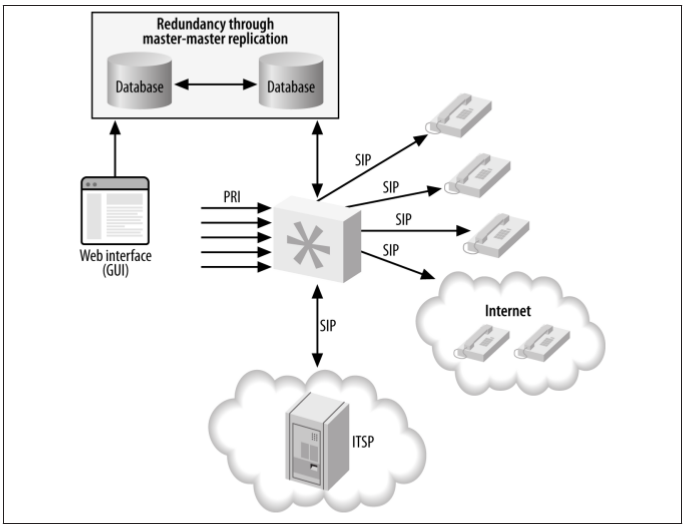
Figure -5. Asterisk database integration, distributed database
Failover can be done natively in Asterisk, as res_odbc and func_odbc 1 do contain configuration options that allow you to specify multiple databases. In res_odbc , you can specify the preferred order for database connections in case one fails. In func_odbc , you can even specify different servers for reading data and writing data through the dialplan functions you create. All of this flexibility allows you to provide a system that works well for your business.
External programs can also be used for controlling failover between systems. The pen application is a load balancer for simple TCP applications such as HTTP or SMTP, which allows several servers to appear as one. This means Asterisk only needs to be configured to connect to a single IP address (or hostname); the pen application will take care of controlling which server gets used for each request.
Asterisk and Distributed Device States
Device states in Asterisk are important both from a software standpoint (Asterisk might need to know the state of a device or the line on a device in order to know whether a call can be placed to it) and from a user’s perspective (for example, a light may be turned on or off to signify whether a particular line is in use, or whether an agent is available for any more calls). From the viewpoint of a queue, it is extremely important to know the status of the device an agent is using in order to determine whether the next caller in the queue can be distributed to that agent. Without knowledge of the device’s state, the queue would simply place multiple calls to the same endpoint.
Once you start expanding your single system to multiple boxes (potentially in multiple physical locations, such as remote or satellite offices), you will need to distribute the device state of endpoints among the systems. The kind of implementation that is required will depend on whether you’re distributing them among systems on the same LAN (low-latency links) or over a WAN (higher-latency links). We’ll discuss two device-state distribution methods in this section: Corosync for low-latency links, and XMPP for higher-latency links.
Distributing Device States over a LAN
The Corosync (previously OpenAIS) implementation was first added to Asterisk in the 1.6.1 branch, to enable distribution of device-state information across servers. The addition of Corosync provided great possibilities for distributed systems, as device-state
awareness is an important aspect of such systems. Previous methods required the use of GROUP() and GROUP_COUNT() for each channel, with that information queried for over Distributed Universal Number Discovery (DUNDi). While this approach is useful in some scenarios (we could use this functionality to look up the number of calls our systems are handling and direct calls intelligently to systems handling fewer calls), as a mechanism for determining device state information it is severely lacking.
Corosync did give us the first implementation of a system that allows the device states and message-waiting indications to be distributed among multiple Asterisk systems . The downside of the Corosync implementation is that it requires all the systems to live on low-latency links, which typically means they all need to reside in the same physical location, attached to the same switch. That said, while the Corosync library does not work across physically separate networks, it does allow a Queue() to reside on one system and queue members to reside on another system (or multiple systems). It does this without requiring us to use Local channels and test their availability through other methods, thereby limiting (or eliminating) the number of connection attempts made across the network, and multiple device ringing.
Using Corosync has an advantage, in that it is relatively easy to configure and get working. The disadvantage is that it is not distributable over physical locations, although we can use XMPP for device-state distribution over a wide area network.
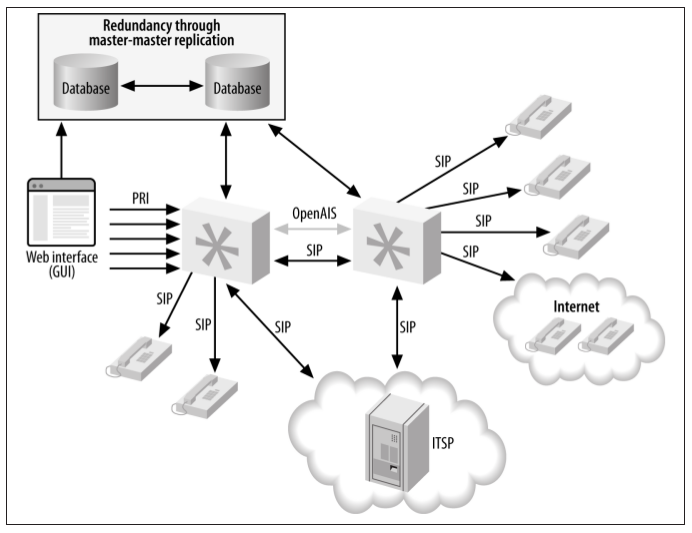
Figure -6. Device state distribution with Corosync
Distributing Device States over a WAN
Because the XMPP protocol is designed for (or at least allows) usage across wide area networks, we can have Asterisk systems at different physical locations distribute device state information to each other . With the Corosync implementation, the library would be used on each system, enabling them to distribute device-state in‐formation. In the XMPP scenario, a central server (or cluster of servers) is used to distribute the state among all the Asterisk boxes in the cluster. Currently, the best application for doing this is the Tigase XMPP server, because of its support for PubSub events. While other XMPP servers may be supported in the future, only Tigase is known to work at this time.
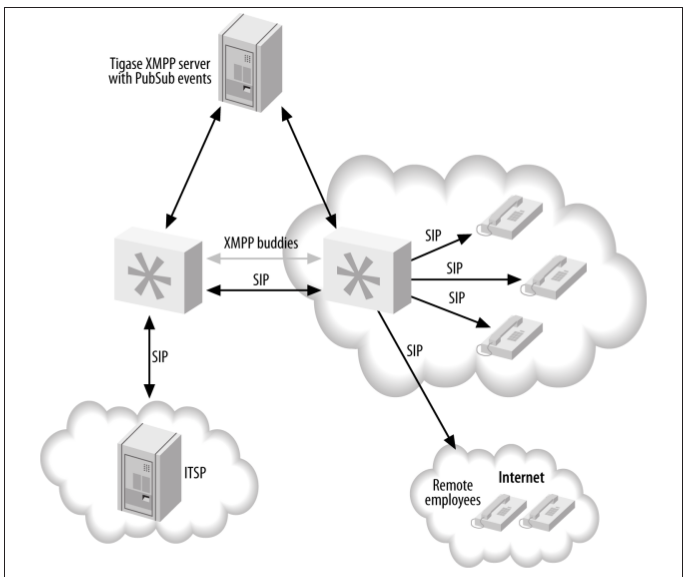
Figure -7. Device-state distribution with XMPP
With XMPP, the queues can be in different physical locations, and satellite offices can take calls from the primary office, or vice versa. This provides another layer of redundancy, because if the primary site goes offline and the ITSP is set up in such a way as to
fail over to another office, the calls can be distributed among those satellite offices until the primary site goes back online. This is quite exciting for many people, as it adds a layer of functionality that was not previously available, and most of it can be done with relatively minimal configuration.
The advantage to XMPP device-state distribution is that it is possible to distribute state to multiple physical locations, which is not possible with Corosync. The disadvantage is that it is more complex to set up (since you need an external service running the Tigase
XMPP server) than the Corosync implementation.
All the agents at the different locations can be loaded into one or more queues, and because we’re distributing device-state information, each queue will know the current state of the agents in the queue and will only distribute callers to the agents as appropriate. Beyond that, we can configure penalties for the queues and/or for the agents in order to get the callers to the best agents if they are available, and only use the other agents when all the best agents are in use.
We can add more agents to the system by adding more servers to the cluster at either the same location or additional physical locations. We can also expand the number of queues we support by adding more servers, each handling a different queue or queues.
A disadvantage to using this system is the way the Queue() application has been developed. Queue() is one of the older applications in Asterisk, and it has unfortunately not kept up with the pace of development in the realm of device-state distribution, so there is no way to distribute the same Queue() across multiple boxes. For example, suppose you have sales queues on two systems. If a caller enters the sales queue on the first
Asterisk system, and then another caller enters the sales queue on the second box, no information will be distributed between those queues to indicate who is first and who is second in line. The two queues are effectively separate. Perhaps future versions of Asterisk will add this capability, but at this time it is not supported. We mention this so you can plan your system accordingly.

Figure -8. Distributed queue infrastructure
Since queues in some implementations (such as call centers) may be required to handle many calls at once, the processing and load requirements for a single system can be quite steep. Having the ability to tap into the same agent resources across multiple systems means we can distribute our callers among multiple boxes, significantly low‐ering the processing requirements placed on any single system. No longer does one system need to do it all—we can break out various components of the system on different servers.
1 thought on “Clustering”
Comments are closed.