NDBCLUSTER (also known as NDB) is an in-memory storage engine offering high-availability and data persistence
features.
The NDBCLUSTER storage engine can be configured with a range of failover and load-balancing options, but it is easiest to start with the storage engine at the cluster level.
MySQL Cluster’s NDB storage engine contains a complete set of data, dependent only on other data within the cluster itself.
The “Cluster” portion of MySQL Cluster is configured independently of the MySQL servers. In a MySQL Cluster, each part of the cluster is considered to be a node.
In many contexts, the term “node” is used to indicate a computer, but when discussing MySQL Cluster it means a process.
It is possible to run multiple nodes on a single computer, for a computer on which one or more cluster nodes are being run we use the term cluster host.
There are three types of cluster nodes, and in a minimal MySQL Cluster configuration, there will be at least three nodes, one of each of these types:
- Management node: The role of this type of node is to manage the other nodes within the MySQL Cluster, performing such functions as providing configuration data, starting and stopping nodes, running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd.
- Data node: This type of node stores cluster data. There are as many data nodes as there are replicas,
times the number of fragments.For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to
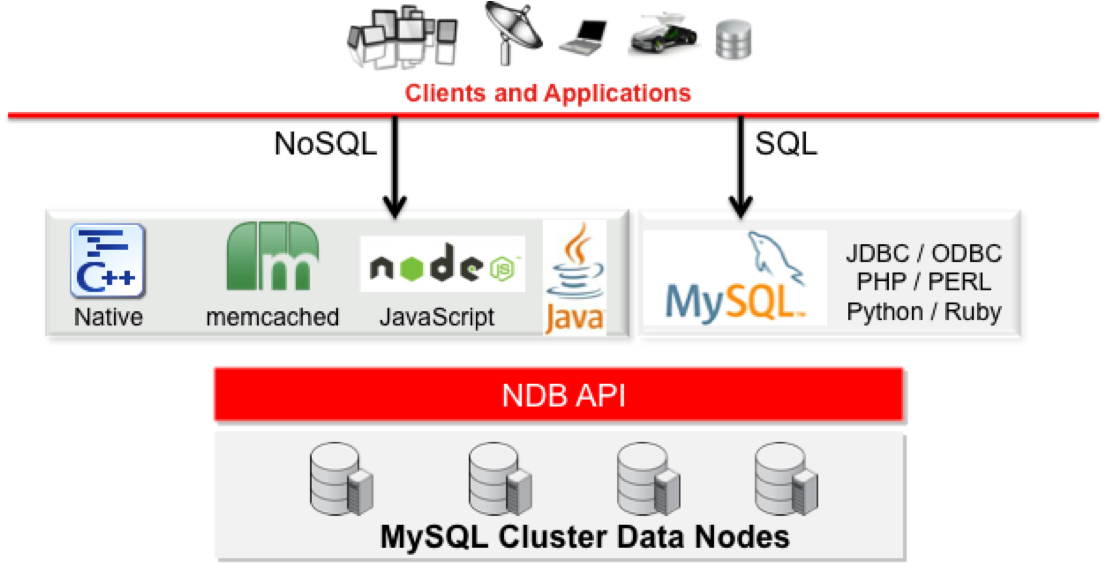
have 2 (or more) replicas to provide redundancy, and thus high availability. A data node is started with the command ndbd. In MySQL Cluster NDB 7.0 and later, ndbmtd can also be used for the data node process.MySQL Cluster tables are normally stored completely in memory rather than on disk (this is why we refer to MySQL Cluster as an in-memory database). - SQL node: This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the NDBCLUSTER storage engine. An SQL node is a mysqld process started with the –ndbcluster and –ndb-connectstring options. An SQL node is actually just a specialized type of API node, which designates any application which accesses MySQL Cluster data. Another example of an API node is the ndb_restore utility that is used to restore a cluster backup. It is possible to write such applications using the NDB API.
It is not realistic to expect to employ a three-node setup in a production environment. Such a configuration provides no redundancy; to benefit from MySQL Cluster’s high-availability features, you must use multiple data and SQL nodes. The use of multiple management nodes is also highly recommended.

Configuration of a cluster involves configuring each individual node in the cluster and setting up individual communication links between nodes.
MySQL Cluster is currently designed with the intention that data nodes are homogeneous in terms of processor power, memory space, and bandwidth.
In addition, to provide a single point of configuration, all configuration data for the cluster as a whole is located in one configuration file.
The management server manages the cluster configuration file and the cluster log.
Each node in the cluster retrieves the configuration data from the management server, and so requires a way to determine where the management server resides.
When interesting events occur in the data nodes, the nodes transfer information about these events to the management server, which then writes the information to the cluster log.
MySQL Cluster can be used with existing MySQL applications written in PHP, Perl, C, C++, Java, Python, Ruby, and so on. Such client applications send SQL statements to and receive responses from MySQL servers acting as MySQL Cluster SQL nodes in much the same way that they interact with standalone MySQL servers.
Management clients connect to the management server and provide commands for starting and stopping nodes gracefully, starting and stopping message tracing (debug versions only), showing node versions and status, starting and stopping backups, and so on. An example of this type of program is the ndb_mgm management client supplied with MySQL Cluster.
MySQL Cluster logs events by category (startup, shutdown, errors, checkpoints, and so on), priority, and severity. Event logs are of the two types listed here:
- Cluster log: Keeps a record of all desired reportable events for the cluster as a whole.
- Node log: A separate log which is also kept for each individual node.
Under normal circumstances, it is necessary and sufficient to keep and examine only the cluster log. The node logs need be consulted only for application development and debugging purposes.
Checkpoint: Generally, when data is saved to disk, it is said that a checkpoint has been reached. More specific to MySQL Cluster, a checkpoint is a point in time where all committed transactions are stored on disk. With regard to the NDB storage engine, there are two types of checkpoints which work together to ensure that a consistent view of the cluster’s data is maintained. These are shown in the following list:
- Local Checkpoint (LCP): This is a checkpoint that is specific to a single node, however, LCPs take place for all nodes in the cluster more or less concurrently. An LCP involves saving all of a node’s data to disk, and so sually occurs every few minutes. The precise interval varies, and depends upon the amount of data stored by the node, the level of cluster activity, and other factors.
- Global Checkpoint (GCP): A GCP occurs every few seconds, when transactions for all nodes are synchronized and the redo-log is flushed to disk.