A Bytecode Example
Though you may not realize it, you have already seen an example of bytecode or at least its human readable format. The output generated by the javap command when we ran it with the -c flag contained a disassembly of each of the methods in the class file.
Let’s consider now the actionPerformed() method of the PointlessButton class:
“public void actionPerformed(java.awt.event.ActionEvent e)
{
donowt.setLabel(“Did Nothing ” + ++count + ” time” + (count == 1 ? “” : “s”));
}”
We compile the PointlessButton.java file with the Java compiler javac and subsequently disassemble the class file with the command:
javap -c -private PointlessButton
In this process, the actionPerformed() method generates the code snippet in the following figure:
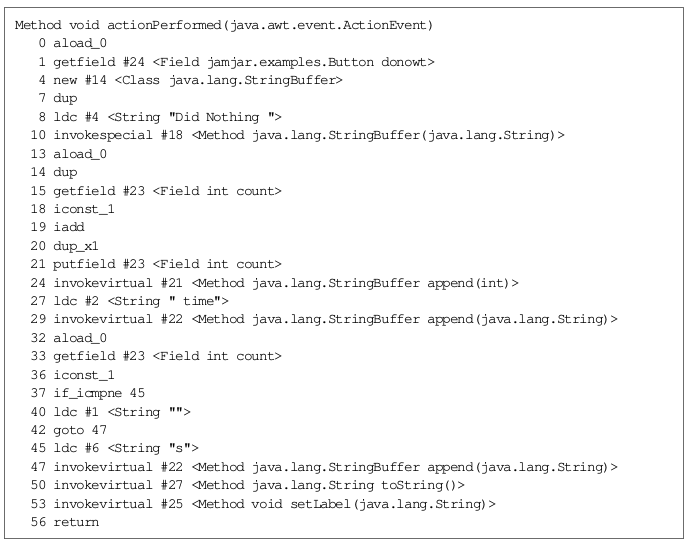
Figure . Disassembled actionPerformed() Method
Let’s look at the following fragment:

The following table explains what each of these instructions does:
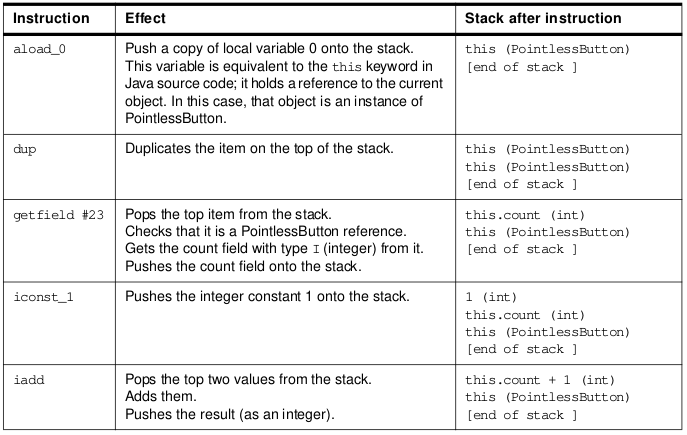

Table . Bytecode Byte-by-Byte
The net of this sequence of operations is to have incremented the count field of the current object by one and left a copy of it on the stack (for use in the next instruction which prints the count).
The equivalent 80×86 code looks like this:
There are a few differences here which we will examine in turn:
• Stack-based architecture vs register-based architecture
The JVM has a stack-based architecture. This means that its instructions deal with pushing values onto, popping values from, and manipulating values on a stack.
The 80×86 processor range from Intel are register-based . They have abnumber of temporary storage areas (registers) some of which are general purpose, others of which have a particular function.
The advantage of making the JVM stack-based is that it is easier to implement a stack-based architecture using registers than vice versa. Thus, porting the JVM to Intel platforms is easy compared with porting a register-based virtual machine to a stack-based hardware platform.
In addition, there are benefits in a stack-based architecture when it comes to establishing what code actually does – more of this in the next chapter.
• Object-oriented vs non-object-oriented
As we have already mentioned, the Java bytecode is object-oriented. This makes for safer code since the JVM checks at run time that the type of fields being accessed or methods invoked for an object are genuinely applicable to that object.
In the 80×86 code snippet, we have variable names to make it clearer what the code is doing, but there are no checks to make sure that the value loaded into the base register really is a pointer to an object of type PointlessButton and that the offset loaded into SI represents the count field of that object.
There is no object-level information at all stored in 80×86 machine code, regardless of the high-level language from which it was compiled! This is so important we will restate it: even if you write programs in Java, once you compile them to 80×86 machine code, all object information is lost and with it a degree of security, since the run-time engine cannot test for the validity of method and/or field accesses.
• Type Safety
While on the subject of type information, a difference to notice is the inclusion of type information in JVM bytecode instructions. The instruction iadd , for example, pops the top two values from the stack, adds them and pushes the return value. The i prefix indicates that the instruction operates on and returns an integer value. The JVM will actually check that the stack contains two integers when the iadd instruction is to be executed. In fact this check is performed by the bytecode verifier, prior to run-time execution.
Contrast this with the 80×86 instructions, which contain no type information. In this case, it is possible that the data loaded into the CX register for incrementing is an integer. However, it is also possible that it is part of a telephone number, an address, or anything different. There are simply no checks performed on data type. This is fine if you can trust your compiler and there is no likelihood of programs being attacked en route to their execution environment. As we have seen, however, in a networked environment, these assumptions cannot be made so lightly.
Not all bytecodes are typed; with a maximum of 256 distinct bytecode values, there are simply not enough to go around. Where a bytecode instruction is typed, the type on which it can operate is indicated by the prefix of the instruction. Table 1 lists the type prefixes and Table 2 shows the bytecodes in detail:
Table 1. Type Prefixes for Bytecode

Table 2. Bytecode Table